

Recently, I had a long conversation with a customer about data lakes vs. data warehouses. Choosing between a data lake and a data warehouse has become a foundational question for every organization entering the AI era. The architecture you choose determines how fast you can analyze data, how costly your pipelines become, and whether your models will be fueled by clean or unreliable inputs.
This guide breaks down, in FAQ format, the differences, tradeoffs, and best practices for 2026. It includes:
• Business-level clarity
• Technical accuracy
• AI-era architectural considerations
Let’s get into it.
A data lake is a low-cost, flexible repository that stores raw data in its native format. This includes:
• JSON
• CSV
• Parquet
• Logs
• Sensor data
• Semi-structured feeds
• Video, audio, and image files
A data warehouse stores structured, cleaned, and schema-enforced tables designed for analytics, BI, SQL workloads, dashboards, and forecasting.
Core takeaway: If the goal is clean reporting, forecasting, and consistent tables, the warehouse wins. If the goal is ML, streaming, or high-volume compute, the lake wins.
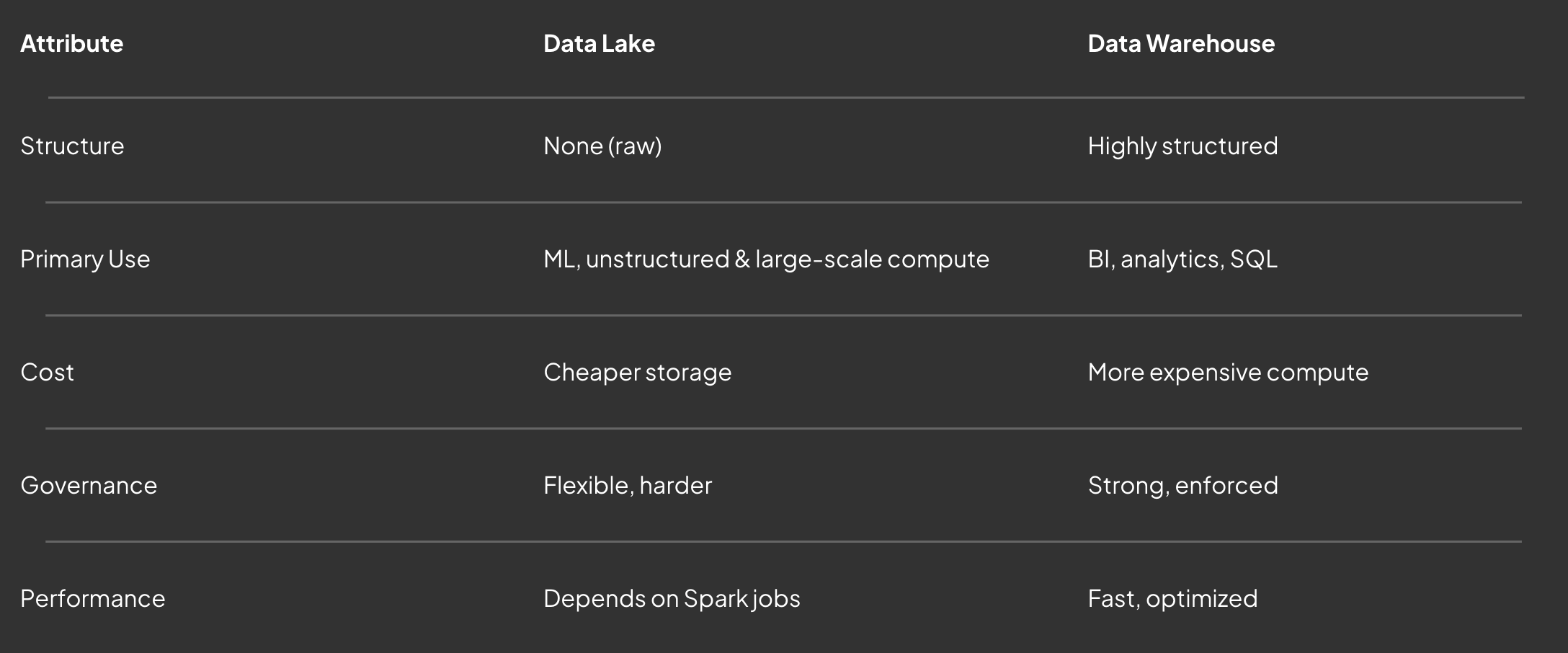
Although their marketing has blurred the lines, their foundations are still different.
Snowflake = Cloud Data Warehouse
• Built for structured, business-critical data
• SQL-optimized
• Strong schemas and governance
• Low maintenance
• High reliability and consistency
Databricks = Apache Spark Lakehouse
• Built for ML training at scale
• Supports Python, Scala, Java, R
• Optimized for unstructured data
• Best for batch + streaming compute
• Requires more engineering discipline
A datalake requires a Spark-native team:
• Data engineers managing clusters
• ML engineers writing distributed jobs
• Platform teams debugging pipeline drift
• Governance owners controlling schema sprawl
• Expertise across multiple runtime languages
Without these, teams often experience:
• Pipeline instability
• Inconsistent tables
• Higher cloud costs
• Long setup and maintenance cycles
• Difficulty enforcing data hygiene
Spark is powerful, but only if you’re built for Spark.
Choose a data warehouse when:
• Most of your data is structured or semi-structured
• You want fast, reliable SQL
• BI dashboards and forecasting matter
• Your team is lean
• You prefer governance over flexibility
• Pipeline reliability matters more than compute versatility
Warehouses reduce cognitive load by enforcing one canonical way to create tables.
This matters when accuracy, consistency, and trust are important.
Choose a data lake with Spark when you’re running:
• Large-scale machine learning
• Real-time recommendations
• Fraud detection
• Log ingestion pipelines
• Compute-heavy ETL
• Multi-language pipelines
• High-volume image/video processing
• Streaming architectures
Warehouse Governance (Snowflake)
• Strong schema enforcement
• Consistent tables
• Easy access control
• Little room for divergence
• Predictable lineage
Datalake Governance (Databricks)
• Highly flexible
• Many ways to define tables
• High schema drift risk
• Requires strong rules and ownership
• Easier to break without noticing
Governance is the hidden cost of a datalake.
Yes - and this hybrid architecture is increasingly becoming the default design for 2026. A modern stack looks like:
1. Raw data lands in a datalake (S3, ADLS, GCS)
2. Transformations produce Parquet/Delta files
3. Cleaned, analytics-ready data flows into the warehouse
4. BI, forecasting, and applications run on the warehouse
It gives you flexibility + structure, the best of both worlds.
Additionally, In a hybrid lake + warehouse model, a data orchestration layer is essential for turning raw, messy inputs into clean, decision-ready tables.
This is where Riley’s Customer Data Orchestration System (CDOS) fits naturally:
• Ingests raw data directly from S3 or cloud storage
• Cleans, standardizes, and reconciles schema drift
• Generates analysis-ready semantic layers
• Publishes structured outputs to Snowflake
• Eliminates the need to maintain Spark pipelines or complex ETL code
You get the flexibility of a datalake without inheriting the full engineering burden — and the reliability of a warehouse without manual modeling work.
AI changes the priority from “store everything” to:
• clean, consistent, high-quality data
• fast retrieval
• clear lineage and metadata
• stable schemas
• governed transformations
Most failed AI initiatives fail because of data quality and warehouses support AI by ensuring:
• stable feature tables
• versioned datasets
• clean historical data
• reliable joins
• consistent metrics
AI doesn’t need a datalake - it needs good data.
Choose Data Warehouse (Snowflake) if you want:
• Fast SQL
• Consistent tables
• Predictable pipelines
• Lower engineering overhead
• Strong governance
• Reliable BI and forecasting
Choose Datalake + Databricks if you:
• Run ML-heavy workloads
• Have multi-language engineering teams
• Process unstructured or streaming data
• Need distributed compute
• Have a strong data engineering function
Choose Hybrid (Lake + Warehouse + CDOS) if you want:
• Flexibility + reliability
• Lower operational burden
• Clean AI-ready data
• Clear lineage
• Faster time to insight
For 80–90% of organizations, the highest-performing architecture is:
Data Lake (S3/Parquet) → CDOS Layer (Riley or similar) → Data Warehouse (Snowflake) → BI + AI Apps
This ensures:
• the lake captures everything
• the CDOS layer creates clean, reliable structure
• the warehouse delivers performance and governance
• analytics and AI run with minimal engineering overhead
The debate isn’t really “Data Lake vs Data Warehouse.”
The real question is:
How much engineering complexity does your organization actually need to produce clean, trustworthy, AI-ready data?
For most teams, the answer is:
Warehouse-first, lake-second, Riley’s CDOS in the middle. The simplest, lowest-cost, most future-proof architecture.
Claudia is the CEO & Co-Founder of Riley AI. Prior to founding Riley AI, Claudia led product, research, and data science teams across the Enterprise and Financial Technology space. Her product strategies led to a $5B total valuation, a successful international acquisition, and scaled organizations to multi-million dollars in revenue. Claudia is passionate about making data-driven strategies collaborative and accessible to every single organization. Claudia completed her MBA and Bachelor degrees at the University of California, Berkeley.